Ho iniziato a sperimentare le reti neurali con il framework pyhton keras e dopo le prime prove mi sono reso conto che l’attività di tuning di una rete neurale è molto delicata.
Quanti nodi servono? Quanti livelli? I batch quanto devono essere grossi? E sopratutto quante epoche di trainng servono?
Come prima attività di tuning mi sono concentrato sulle epoche, un numero eccessivo di epoche porta a un overfit della rete, mentre un numero basso porta a una rete troppo poco addestrata. L’idea che mi sono è che allenare una rete neurale è come allenare un pilota su un circuito di Formula 1. Il pilota sale sulla macchina e inizia a guidare a ogni giro migliora le proprie prestazioni, più giri fa e più migliora. Se però il pilota si allena troppo sul medesimo circuito lo impara a memoria e quando cambia circuito le sue prestazioni saranno scarse. L’obiettivo è quindi allenare il pilota senza fargli imparare a memoria il tracciato. Con l’esempio è evidente che se il pilota si allena su un certo tipo di pista e la pista su cui è chiamato a misurarsi ha caratteristiche diverse i risultati del pilota saranno pessimi. Allenare un pilota su un circuito di Formula 1 e farlo gareggiare su un circuito da rally porterà a pessimi risultati.
Per valutare la bontà dell’allenamento utilizzo l’errore quadratico medio tra il risultato del set di dati di test e il risultato stimato dalla rete neurale. Alleno il mio “pilota” ossia la rete neurale facendogli fare un certo numero di giri di allenamento (epoche) sulla pista di allenamento (training set) e poi lo porto sulla pista di test (test set) per verificare quanto sono buone le sue prestazioni. Ripeto l’esperimento 30 volte a parità di numero di giri di test (epoche) e poi faccio variare il numero di giri (epoche). Eseguire l’esperimento 30 volte serve per avere un campione sufficiente per una statistica di base, ogni esperimento produce pesi diversi e quindi reti neurali che si comportano in modo diverso.
L’asset su cui ho allenato la mia rete neurale è l’azione Telecom, la speranza è di ottenere risultati positivi su un asset in forte calo. Il codice del ciclo di test sulle epoche è il seguente
from pandas import DataFrame
from math import sqrt
import matplotlib
# be able to save images on server
#matplotlib.use('Agg')
from matplotlib import pyplot
def experiment(repeats=5, epochs=2):
error_scores = list()
for r in range(repeats):
lstm = testasset("TIT", epochs=epochs)
rmse = sqrt(lstm.stats())
print('%d) Test RMSE: %.3f' % (r+1, rmse))
error_scores.append(rmse)
return error_scores
repeats = 30
results = DataFrame()
epochs = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50]
for e in epochs:
results[str(e)] = experiment(repeats, e)
print(results.describe())
results.boxplot()
pyplot.savefig('boxplot_epochs.png')
Per farlo girare c’è voluto diverso tempo, sopratutto per l’apprendimento con 20 e 50 epoche, complessivamente l’esecuzione è durata poco più di due giorni, qui la tabelle dei tempi di esecuzione
ore gg 0 0 0 1 0.4375 0.018229167 2 0.875 0.036458333 3 1.3125 0.0546875 4 1.75 0.072916667 5 2.1875 0.091145833 6 2.625 0.109375 7 3.0625 0.127604167 8 3.5 0.145833333 9 3.9375 0.1640625 10 4.375 0.182291667 20 8.75 0.364583333 50 21.875 0.911458333
Nella seguente tabella sono riportati i dati statistici delle misurazioni di esecuzione con le diverse epoche:
1 2 3 4 5 6 \
count 30.000000 30.000000 30.000000 30.000000 30.000000 30.000000
mean 0.038587 0.041846 0.034651 0.035500 0.032625 0.032489
std 0.014706 0.013233 0.009586 0.010110 0.009148 0.009238
min 0.020083 0.019384 0.022519 0.022931 0.021452 0.021175
25% 0.026908 0.034563 0.027189 0.027118 0.025462 0.024630
50% 0.034167 0.039058 0.031203 0.033280 0.031137 0.029748
75% 0.046000 0.049699 0.040562 0.042590 0.038665 0.036789
max 0.075115 0.075003 0.060300 0.062060 0.055277 0.053957
7 8 9 10 20 50
count 30.000000 30.000000 30.000000 30.000000 30.000000 30.000000
mean 0.034010 0.027564 0.029000 0.028845 0.020712 0.018076
std 0.012303 0.008566 0.010543 0.010209 0.007081 0.006426
min 0.019001 0.018077 0.017641 0.016518 0.011808 0.009376
25% 0.023905 0.020850 0.020434 0.021110 0.015664 0.012611
50% 0.030288 0.024321 0.027368 0.027386 0.018326 0.018031
75% 0.043142 0.032642 0.033461 0.031322 0.024690 0.022165
max 0.062863 0.055480 0.063527 0.058419 0.037421 0.031675
Il set di dati di addestramento non era particolarmente corposo, ca 4700 campioni. Gli stessi dati rappresentati con un grafico a box mostra l’andamento decrescente dell’errore quadratico medio, segno che l’addestramento è efficace e non siamo in una situazione di overfit.
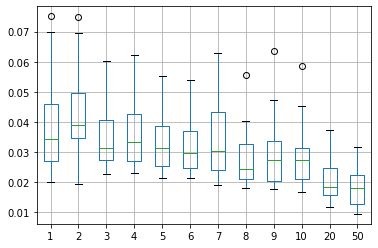
Un ultimo confronto utile è la stima dei valori fatta dale due reti, addestrate agli estremi, 1 epoca e 50 epoche.
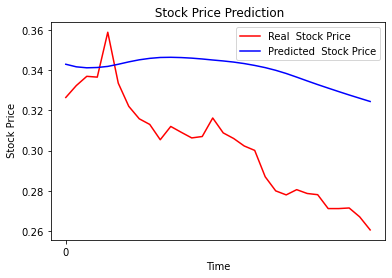
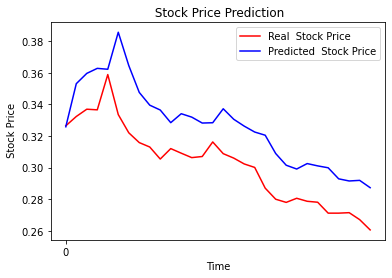
Il confronto tra i due grafici mette in evidenza il comportamento del “pilota” addestrato bene, rispetto al “pilota” principiante che fatica a star dietro ai rapidi cambi di direzione. La lunghezza del data set coincide anch’esso sull numero di epoche necessarie a un buon addestramento. Tornando alla metafora del pilota, se la pista è lunga, con molti cambi di direzione, accelerazioni, frenate, paraboliche e altro, il pilota riesce ad allenarsi con pochi giri. Se la pista è breve il pilota dovrà ripetere la pista diverse volte per avere un buon allenamento. Maggiore è il numero di epoche necessarie all’addestramento, maggiore è la probabilità di overfit. Benché i risultati non evidenzino l’overfit con il degrado delle performance, dallo studio del grafico con 50 epoche, l’overfit risulta evidente. Lo stesso grafico con 10 epoche risulta più morbido e accompagna bene la curva del titolo.
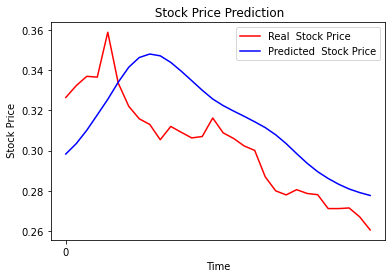
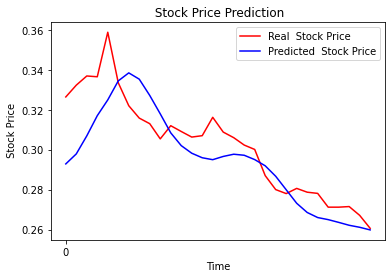
Ciò che però sembra aver appreso la rete neurale è di riproporre in modo molto fedele i movimenti che il titolo ha fatto il giorno precedente. La rete non sembra in grado di anticipare i movimenti del titolo con le sole informazioni disponibili e la miglio strategia che riesce ad attuare è d’inseguimento. Ai fini dello studio di tecniche di AI l’esercizio è stato utile, ai fini di algotrading un po’ meno.
Lascia un commento